
퍼셉트론
입력을 받아서 가중치 곱하고 더해서 출력 내보내는 계산 단위 → 이게 하나의 노드(뉴런)
여러 퍼셉트론(노드)이 모여서 한 층(layer)을 만듦
층을 여러 개 쌓으면 다층 퍼셉트론(MLP)
단층 퍼셉트론과 다층 퍼셉트론
단층 퍼셉트론은 입력층,출력층이 각각 1개라고 가정했을 때 출력층에 y=w * x + b라고 하면 x가 들어가서 w,b에 맞춰서 예측값이 나오고 w,b가 갱신되는 구조라면
다층 퍼셉트론은 y = w * x + b가 노드별로 존재하는 것은 동일하지만, 각 노드별로 가중치와 편향의 값이 다름.
다층 퍼셉트론 원리
맨 처음에 x값을 주면 랜덤으로 설정된 w,b로 인해 예측값을 만들고, 기존 정답 y를 기반으로 손실함수를 만들어 손실함수에서의 w값에 대응되는 기울기를 구해 w값을 조정한다. 노드별로.
MLP
퍼셉트론은 선형 모델. 층 하나로는 XOR 같은 비선형 문제 못 풂.
MLP는 퍼셉트론 여러 개 + 비선형 활성화 함수(ReLU)로 층을 쌓아 비선형 문제 해결 가능.
ReLU
ReLU (Rectified Linear Unit) : 뉴런(노드)에서 계산된 값이 0보다 크면 그대로 두고, 0보다 작으면 0으로 바꿔주는 함수입니다.
공식 : ReLU(x) = max(0, x)
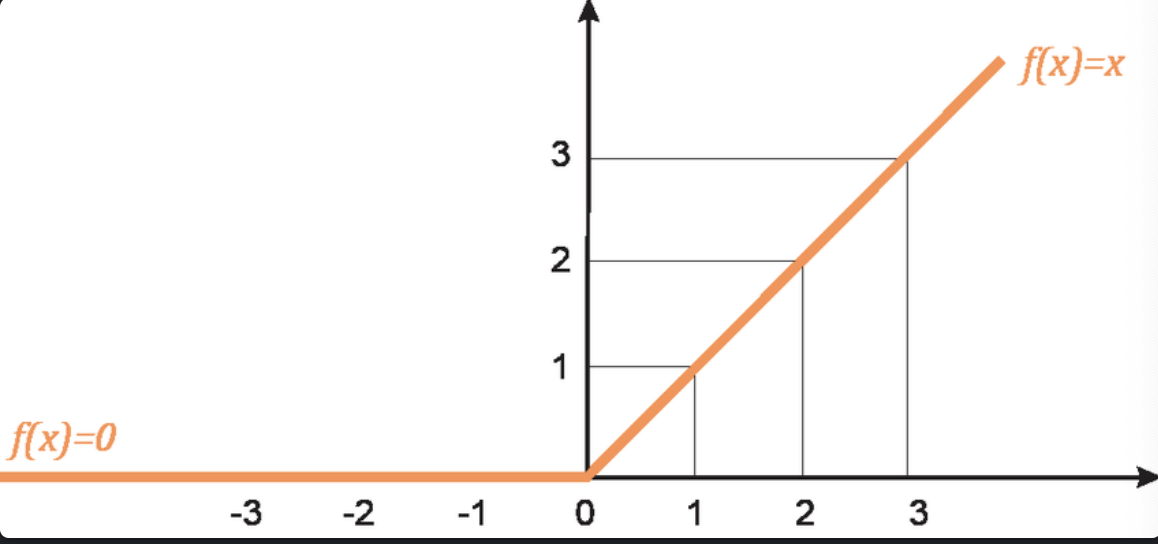
ReLU를 넣는 이유
층을 여러 개 쌓아도 중간에 비선형 함수가 없으면 전체가 다시 선형 함수랑 같아짐.
(ReLU같은 활성화 함수가 없으면 노드를 많이 하나 적게하나 같은 결과가 나옴)
실습 흐름
1. 선형 데이터 → 단층 퍼셉트론 → 성공
2. XOR 데이터 → 단층 퍼셉트론 → 실패
3. XOR 데이터 → MLP(다층 퍼셉트론) + ReLU → 성공
1.선형 데이터 → 단층 퍼셉트론 → 성공
코드
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
# Custom Dataset
class CustomLinearDataset(Dataset):
def __init__(self):
super().__init__()
self.x_data = torch.linspace(0, 10, 100).unsqueeze(1)
self.y_data = 2 * self.x_data + 1 + torch.randn_like(self.x_data) * 0.5
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
# 파라미터
batch_size = 100
num_epochs = 50
lr = 0.01
# 데이터 로더
dataset = CustomLinearDataset()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 모델, 손실함수, 옵티마이저
model = nn.Linear(1, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
# 학습 루프
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
y_pred = model(batch_x)
loss = criterion(y_pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")
# 결과 확인
print("최종 가중치(w):", model.weight.item())
print("최종 편향(b):", model.bias.item())
결과
Epoch 0 | Loss: 171.5973
Epoch 10 | Loss: 0.2983
Epoch 20 | Loss: 0.2961
Epoch 30 | Loss: 0.2940
Epoch 40 | Loss: 0.2922
최종 가중치(w): 1.9831370115280151
최종 편향(b): 1.0453205108642578
loss가 점차 줄어들고 있고 w랑 b가 각각 2랑 1에 가까워진 것을 확인할 수 있음 -> 성공
2.XOR 데이터 → 단층 퍼셉트론 → 실패
코드
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
class CustomLinearDataset(Dataset):
def __init__(self):
super().__init__()
self.x_data = torch.tensor([[0,0],[1,0],[0,1],[1,1]],dtype=torch.float32) #xor의 x값
self.y_data = torch.tensor([[0],[1],[1],[0]],dtype=torch.float32) #xor의 y값
self.y_data += torch.randn_like(self.y_data) * 0.05
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
batch_size = 4 #batch_size는 100으로 해봤자 의미 없으니 4로 바꿈
num_epochs = 50
lr = 0.01
# 데이터 로더
dataset = CustomLinearDataset()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 모델, 손실함수, 옵티마이저
model = nn.Linear(2, 1) #입력값이 0,0처럼 2개이므로 앞의 숫자를 2로 바꿈
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
# 학습 루프
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
y_pred = model(batch_x)
loss = criterion(y_pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")
# 비선형 데이터나 가중치나 편향의 정답값은 없음 loss가 줄어드는지만 확인하면 됨
결과
Epoch 0 | Loss: 0.5325
Epoch 10 | Loss: 0.4293
Epoch 20 | Loss: 0.3722
Epoch 30 | Loss: 0.3395
Epoch 40 | Loss: 0.3199
이 경우는 XOR이라는 비선형 데이터를 x,y에 넣었는데 y에다가 noise를 추가했음에도 불구하고 loss가 줄어드는 것을 확인할 수 있음
loss가 줄어들면 단층 퍼셉트론은 비선형 문제를 해결할 수 없다는 것이 틀린 건가? -> X데이터가 XOR처럼 완전한 비선형 구조여도 직선에 미약하게나마 근사할 수 있기 떄문에 loss가 줄어들 수 밖에 없음(loss가 아예 줄어 들지 않는 경우 ex. 모델 구조가 아예 틀린 경우, 학습이 아예 안된 경우 등)
아무리 반복해서 학습시켜도 loss가 0이 결코 될 수 없음 -> 단층 퍼셉트론이 비선형성 문제를 완전히 풀 수 없다는 증거임
예외상황
그럼 이러한 예외 상황(loss가 안줄어들 거라고 생각했는데 줄어듬)이 발생했으니 단층 퍼셉트론에서는 비선형 문제를 풀 때 loss가 0이 될 수 없음을 증명해보자
일단 단층 퍼셉트론에서 선형 문제를 풀 때는 loss가 0이 될 수 있으나 비선형 문제를 풀떄는 그럴 수 없음을 보여야 한다.
이를 위해서는 일단 공정하게 둘 다 noise를 제거해야한다.(noise가 있을 경우 y=2x+1과 같은 선형 문제도 loss가 0이 될 수 없게되기 때문)
1)선형 데이터 → 단층 퍼셉트론(loss가 0이 나와야함)
noise를 제거하고 반복횟수를 늘려서 loss가 0이 나오는지 확인해보자
코드
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
class CustomLinearDataset(Dataset):
def __init__(self):
super().__init__()
self.x_data = torch.linspace(0, 10, 100).unsqueeze(1)
self.y_data = 2 * self.x_data + 1 #noise제거
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
batch_size = 100
num_epochs = 1000 #반복 횟수를 늘림
lr = 0.01
dataset = CustomLinearDataset()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
model = nn.Linear(1, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
y_pred = model(batch_x)
loss = criterion(y_pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")
#loss만 볼꺼임(가중치,편향x)
결과
Epoch 0 | Loss: 149.8277
Epoch 10 | Loss: 0.2223
Epoch 20 | Loss: 0.2012
Epoch 30 | Loss: 0.1822
Epoch 40 | Loss: 0.1649
...
Epoch 780 | Loss: 0.0001
Epoch 790 | Loss: 0.0001
Epoch 800 | Loss: 0.0001
Epoch 810 | Loss: 0.0001
Epoch 820 | Loss: 0.0001
Epoch 830 | Loss: 0.0001
Epoch 840 | Loss: 0.0001
Epoch 850 | Loss: 0.0001
Epoch 860 | Loss: 0.0000
Epoch 870 | Loss: 0.0000
Epoch 880 | Loss: 0.0000
loss가 0이됨을 확인할 수 있음 -> 완료
2)XOR 데이터 → 단층 퍼셉트론(loss가 0이 나오면 안됨)
얘도 noise 없애고 1000번 동일하게 돌려서 loss가 나오는지 확인
코드
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
class CustomLinearDataset(Dataset):
def __init__(self):
super().__init__()
self.x_data = torch.tensor([[0,0],[1,0],[0,1],[1,1]],dtype=torch.float32)
self.y_data = torch.tensor([[0],[1],[1],[0]],dtype=torch.float32) #noise 제거
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
batch_size = 4
num_epochs = 1000 #1000번 반복
lr = 0.01
dataset = CustomLinearDataset()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
model = nn.Linear(2, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
y_pred = model(batch_x)
loss = criterion(y_pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")
결과
Epoch 0 | Loss: 0.5954
Epoch 10 | Loss: 0.4315
Epoch 20 | Loss: 0.3456
Epoch 30 | Loss: 0.3006
Epoch 40 | Loss: 0.2770
...
Epoch 130 | Loss: 0.2506
Epoch 140 | Loss: 0.2505
Epoch 150 | Loss: 0.2504
Epoch 160 | Loss: 0.2504
Epoch 170 | Loss: 0.2504
Epoch 180 | Loss: 0.2503
Epoch 190 | Loss: 0.2503
Epoch 200 | Loss: 0.2503
Epoch 210 | Loss: 0.2502
Epoch 220 | Loss: 0.2502
Epoch 230 | Loss: 0.2502
Epoch 240 | Loss: 0.2502
Epoch 250 | Loss: 0.2502
Epoch 260 | Loss: 0.2501
Epoch 270 | Loss: 0.2501
Epoch 280 | Loss: 0.2501
Epoch 290 | Loss: 0.2501
Epoch 300 | Loss: 0.2501
Epoch 310 | Loss: 0.2501
Epoch 320 | Loss: 0.2501
Epoch 330 | Loss: 0.2501
Epoch 340 | Loss: 0.2501
Epoch 350 | Loss: 0.2501
Epoch 360 | Loss: 0.2501
Epoch 370 | Loss: 0.2500
Epoch 380 | Loss: 0.2500
...
Epoch 930 | Loss: 0.2500
Epoch 940 | Loss: 0.2500
Epoch 950 | Loss: 0.2500
Epoch 960 | Loss: 0.2500
Epoch 970 | Loss: 0.2500
Epoch 980 | Loss: 0.2500
Epoch 990 | Loss: 0.2500
계속 loss가 감소하다가 결국 0.25에 수렴하는 것을 확인함. 즉 0이 될 수 없음을 확인함. -> 완료
결론
1)과 2)에 의하여 단층 퍼셉트론은 비선형 문제를 해결할 수 없음.
3. XOR 데이터 → MLP(다층 퍼셉트론) + ReLU → 성공
코드
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
# 1. 데이터셋 정의 (기존 그대로)
class CustomXORDataset(Dataset):
def __init__(self):
super().__init__()
self.x_data = torch.tensor([[0,0],[1,0],[0,1],[1,1]], dtype=torch.float32)
self.y_data = torch.tensor([[0],[1],[1],[0]], dtype=torch.float32) #MLP는 정확한 학습을 위해 noise제거
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
# 2. 하이퍼파라미터
batch_size = 4
#MLP는 단층 퍼셉트론과 달리 학습이 가능하니 num_epoch와 lr을 증가시켜 더 오래 더 빨리 수렴하도록 설정.
num_epochs = 1000
lr = 0.1
# 3. 데이터로더
dataset = CustomXORDataset()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 4. MLP 모델 (은닉층 추가 + ReLU)
model = nn.Sequential(
nn.Linear(2, 4), # 입력 2차원 -> 은닉층 4차원
nn.ReLU(),
nn.Linear(4, 1), # 은닉층 -> 출력층
nn.Sigmoid() # 이진 출력이므로 Sigmoid
)
# 5. 손실함수, 옵티마이저
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
# 6. 학습 루프
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
y_pred = model(batch_x)
loss = criterion(y_pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")
# 7. 예측 확인
with torch.no_grad():
test = torch.tensor([[0,0],[1,0],[0,1],[1,1]], dtype=torch.float32)
pred = model(test)
print("\nPredictions:")
print(pred)
결과
Epoch 0 | Loss: 0.6952
Epoch 10 | Loss: 0.6839
Epoch 20 | Loss: 0.6763
Epoch 30 | Loss: 0.6709
Epoch 40 | Loss: 0.6654
Epoch 50 | Loss: 0.6595
Epoch 60 | Loss: 0.6525
...
Epoch 950 | Loss: 0.0262
Epoch 960 | Loss: 0.0255
Epoch 970 | Loss: 0.0249
Epoch 980 | Loss: 0.0244
Epoch 990 | Loss: 0.0238
Predictions:
tensor([[0.0401],
[0.9774],
[0.9838],
[0.0129]])
Loss가 꾸준히 감소하고, 예측값이 원래 정답인 0,1,1,0과 근접한 0.04,0.97,0.98,0.01이 나온 것을 확인 할 수 있음 -> 완료
마무리
1. 선형 데이터 → 단층 퍼셉트론 → 성공
2. XOR 데이터 → 단층 퍼셉트론 → 실패
3. XOR 데이터 → MLP(다층 퍼셉트론) + ReLU → 성공
결과적으로 위와 같은 흐름을 통해 비선형 데이터에서 MLP의 필요성을 알게됨