
1. Custom Dataset 클래스 직접 작성하고 DataLoader로 불러오기
Custom Dataset이란
PyTorch는 데이터를 불러오는 방법을 Dataset이라는 클래스로 정해두었습니다.
MNIST 같은 건 이미 만들어져 있는 Dataset이라서 그냥 불러오면 되지만, 내가 만든 데이터는 내 Dataset 클래스를 직접 만들어야 합니다.
1.torch.utils.data.Dataset 상속하기
파이토치가 “데이터셋”이라고 인정하려면 torch.utils.data.Dataset을 상속해야 합니다.
그리고 3가지 메서드는 꼭 만들어야 합니다
init : 데이터를 처음에 어떻게 준비할지
len : 데이터가 몇 개나 있는지 알려주기
getitem : 인덱스로 원하는 데이터를 꺼내오기
2.간단한 toy 데이터 준비하기
복잡한 파일 말고, 연습용으로 torch.linspace(숫자 범위 내에서 같은 간격으로 수를 만들어줌) 같은 걸로 숫자 배열을 만듭니다.
저는 x 값은 0부터 10까지 100개, y 값은 y = 2x + 1(+노이즈)같은 간단한 선형 방정식으로 만들 것입니다.
(노이즈를 넣어야 더 실제에 가까운 데이터가 되고, 노이즈가 있어도 가중치와 편향을 잘 추정하는지 알 수 있습니다.)
3.DataLoader로 연결해서 batch 단위로 불러보기
이건 지난 day1처럼 그냥 batch_size(여기서는 4)에 맞게 불러오면 됩니다.
흐름
1.import
2.클래스 정의
2-1.초기화 함수(x,y값 생성)
2-2.데이터 개수 반환 함수
2-3.데이터 반환 함수
3.데이터 객체 생성
4.dataloader로 묶음
5.반복문(x,y를 4개씩 출력)
코드
#1.import
import torch
from torch.utils.data import Dataset, DataLoader
#2.클래스 생성
class CustomLinearDataset(Dataset): #Dataset을 상속하고 있음
#2-1.초기화 함수(x,y생성)
def __init__(self):
super().__init__()
self.x_data = torch.linspace(0,10,100).unsqueeze(1) #unsqueeze로 (100,)의 형태인 shape를 (100,1)로 만들어 선형 회귀 모델에서 받는 입력의 형태로 맞춤
self.y_data = 2 * self.x_data + 1 + torch.randn_like(self.x_data) * 0.5
#2-2.데이터 개수 반환 함수
def __len__(self):
return len(self.x_data)
#2-3.값 반환 함수
def __getitem__(self,idx):
return self.x_data[idx], self.y_data[idx]
#3.객체 생성(dataset)
dataset = CustomLinearDataset()
#4.dataloader로 묶음
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
#5.반복문(x,y를 4개씩 출력)
for batch in dataloader:
x_batch,y_batch = batch
print(f"x_batch {x_batch}")
print(f"y_batch {y_batch}")
결과
x_batch tensor([[0.4040],
[5.7576],
[7.2727],
[4.7475]])
y_batch tensor([[ 1.2421],
[13.2353],
[15.8072],
[ 9.9576]])
x_batch tensor([[6.0606],
[7.4747],
[3.5354],
[4.9495]])
y_batch tensor([[14.1856],
[16.1461],
[ 7.7556],
[11.7264]])
...
x와 y가 batch_size에 맞게 4개씩 출력되는 것을 확인할 수 있음
2.각 batch size 별로 학습곡선을 그래프로 그려 비교
흐름
1.import
2.Dataset 클래스 정의
3.파라미터 설정
4.loss담을 dict정의
5.batch_size별 학습 반복
-dataset 및 dataloader
-모델/손실함수/옵티마이저
-학습루프
-학습기록
6.그래프 그리기
특징
모델은 nn.Linear(1,1)
loss함수는 MSELoss()를 사용
코드
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
# Custom Dataset 클래스 (이미 위에서 완성함)
class CustomLinearDataset(Dataset):
def __init__(self):
super().__init__()
self.x_data = torch.linspace(0, 10, 100).unsqueeze(1)
self.y_data = 2 * self.x_data + 1 + torch.randn_like(self.x_data) * 0.5
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
# 실험 파라미터
batch_sizes = [1, 4, 100] #batch_size를 1,4,100으로
num_epochs = 50 #50번 반복
lr = 0.01 #learning_rage는 0.01로
# 손실 기록
losses_dict = {} #각 batch_size별 loss들을 key,value값으로 저장
# 각 batch size 실험
for batch_size in batch_sizes: #1,4,100
dataset = CustomLinearDataset() #dataset 객체 생성
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
model = nn.Linear(1, 1) #Linear라는 model사용
criterion = nn.MSELoss() #MSELoss라는 loss함수 사용
optimizer = torch.optim.SGD(model.parameters(), lr=lr) #SGD 옵티마이저 사용
losses = [] #각 batch_size당 loss들을 담는 losses가 1개씩
for epoch in range(num_epochs):
epoch_loss = 0.0 #한 epoch에서 나오는 loss 총합
for batch_x, batch_y in dataloader: #한 epoch에서 여러번 batch_size에 맞춰 불러옴
y_pred = model(batch_x) #예측(순전파)
loss = criterion(y_pred, batch_y) #loss함수
optimizer.zero_grad() #기울기 초기화(여기서는 먼저옴)
loss.backward() #역전파(기울기 계산)
optimizer.step() #w갱신
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
losses.append(avg_loss) #epoch별 평균 loss를 losses에 더함
losses_dict[batch_size] = losses #batch_size별 loss들을 dict에 저장
print(f"[Batch size {batch_size}] done.")
# 그래프 시각화
for batch_size, losses in losses_dict.items():
plt.plot(losses, label=f"Batch size {batch_size}") #batch_size별 losses를 그래프로 나영
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve Comparison')
plt.legend()
plt.show()
결과
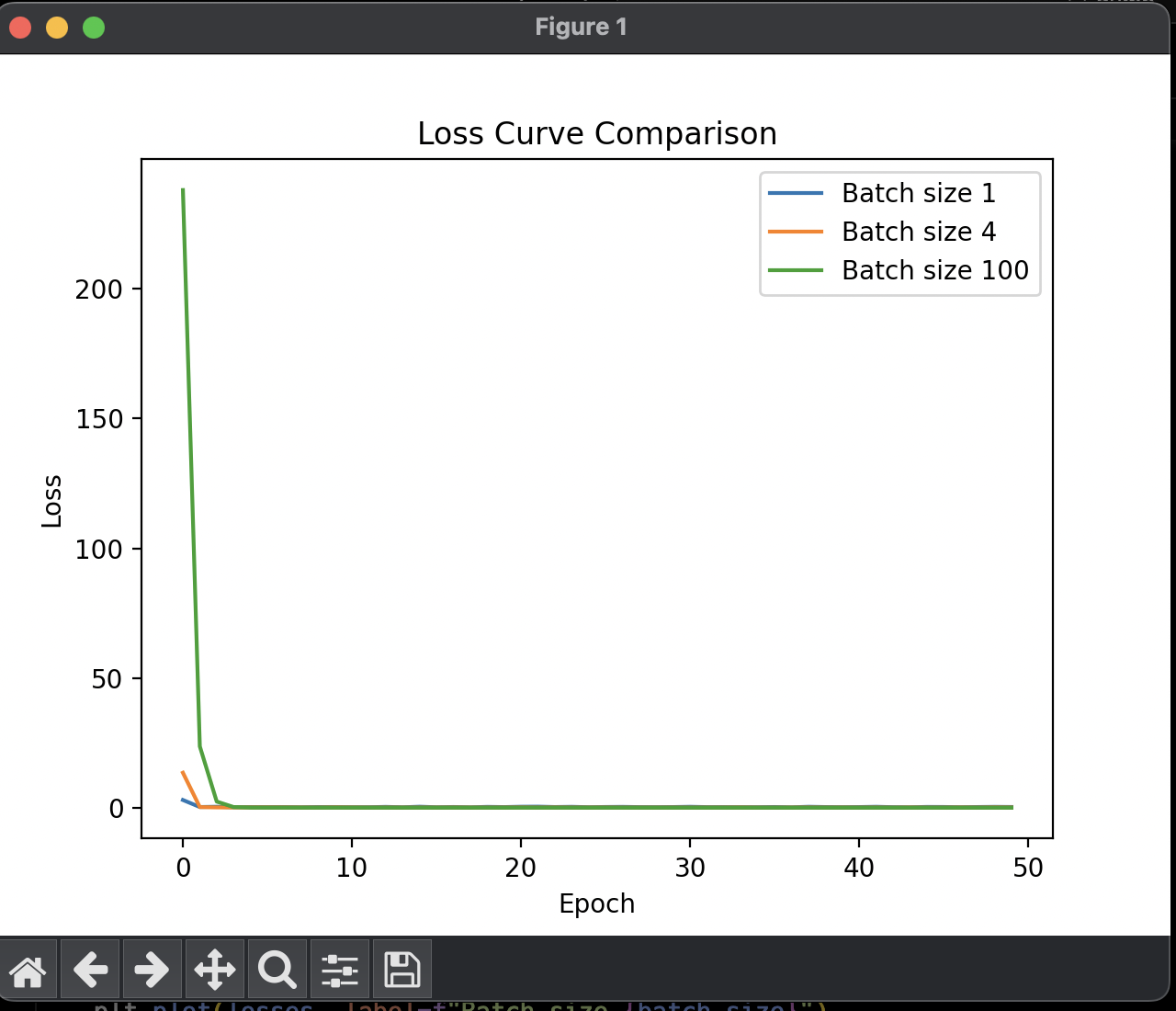
왜 이런 결과가 나왔는지는 다음에 알아보자
'ai' 카테고리의 다른 글
| pytorch-Day3 : 단층 퍼셉트론에서 비선형 문제를 완벽하게 풀수 없음을 증명 (3) | 2025.07.30 |
|---|---|
| pytorch-Day5 : MLP로 MNIST 손글씨 분류 – 전체 학습 흐름 구현 (1 Epoch) (1) | 2025.07.28 |
| pytorch-Day4 : XOR 문제를 해결하는데 사용한 MLP코드에서 파라미터를 변경하며 정확도 올려보기 + MNIST Dataset 다운로드 & 로딩 테스트 (2) | 2025.07.11 |
| pytorch-Day1 : mini-batch 실습 및 loss함수 시각화(by Dataset/DataLoader && matplotlib) (2) | 2025.07.09 |
| pytorch-Day0 (0) | 2025.07.09 |